US Household Income Project
- nalwogaimmaculate3
- Sep 13, 2025
- 3 min read
Updated: Feb 22
Project Type: Personal Project
Tools Used: MySQL, Stored Procedures, Joins, Aggregations, Data Cleaning Techniques.
Link to Code:
Overview:
In this project we walk through the process of a full data workflow using SQL —
from cleaning the raw data to uncovering insights and building an automated cleaning system. The dataset contains U.S. household income information across states, cities, and counties. I approach this project in three phases.
Data Cleaning
Exploratory Data Analysis (EDA)
Automated Data Cleaning Workflow
Phase 1: Data Cleaning
Objective: Prepare the raw data for analysis by resolving inconsistencies, duplicates, and missing values.
First, let's take a look at the data:

Table Inspection and Column Renaming
SELECT *
FROM us_household_income;
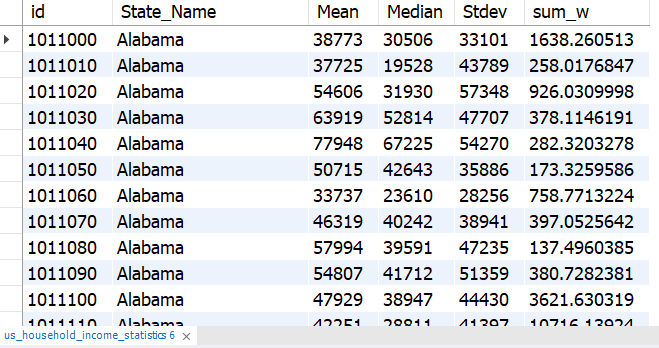
SELECT *
FROM us_household_income_statistics;
ALTER TABLE us_household_income_statistics
RENAME COLUMN `id` TO `id`;
Row Count and Duplicate Detection
SELECT COUNT(id)
FROM us_household_income;
SELECT COUNT(id)
FROM us_household_income_statistics;
SELECT id, COUNT(id)
FROM us_household_income
GROUP BY id
HAVING COUNT(id) > 1;
SELECT * FROM (
SELECT row_id, id,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) AS row_num
FROM us_household_income) row_tab
WHERE row_num > 1;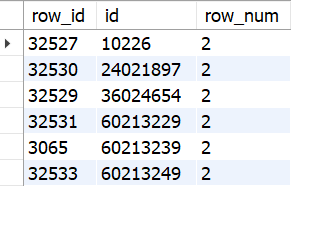
Duplicate Removal
DELETE FROM us_household_income
WHERE row_id IN (
SELECT row_id FROM (
SELECT row_id, id,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY id) AS row_num
FROM us_household_income
) row_tab
WHERE row_num > 1
);
Standardizing Text Fields
SELECT DISTINCT State_Name
FROM us_household_income;
UPDATE us_household_income
SET State_Name = 'Alabama'
WHERE State_Name = 'alabama';
UPDATE us_household_income
SET State_Name = 'Georgia'
WHERE State_Name = 'georia';
UPDATE us_household_income
SET State_Name = UPPER(State_Name);
UPDATE us_household_income
SET County = UPPER(County);
UPDATE us_household_income
SET State_ab = UPPER(State_ab);
UPDATE us_household_income
SET City = UPPER(City);
UPDATE us_household_income
SET Place = UPPER(Place);
UPDATE us_household_income
SET Type = 'Borough'
WHERE Type = 'Boroughs';
UPDATE us_household_income
SET Type = 'CDP'
WHERE Type = 'CPD';
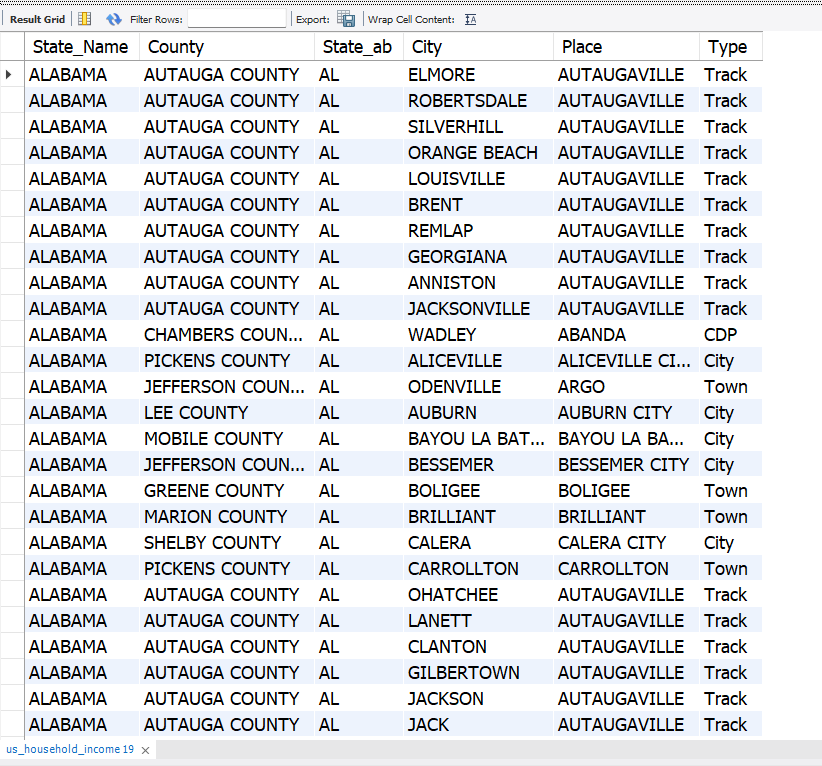
Handling Missing Values
SELECT * FROM us_household_income WHERE Place = '';
UPDATE us_household_income
SET Place = 'Autaugaville'
WHERE County = 'Autauga County' AND City = 'Vinemont';Land and Water Validation
SELECT ALand, AWater
FROM us_household_income
WHERE ALand = 0 OR ALand = '' OR ALand IS NULL;
SELECT ALand, AWater
FROM us_household_income
WHERE AWater = 0 OR AWater = '' OR AWater IS NULL;
SELECT ALand, AWater
FROM us_household_income
WHERE (ALand = 0 OR ALand = '' OR ALand IS NULL)
AND (AWater = 0 OR AWater = '' OR AWater IS NULL);
Phase 2: Exploratory Data Analysis
Objective: Analyze geographic and income patterns across U.S. states and cities.
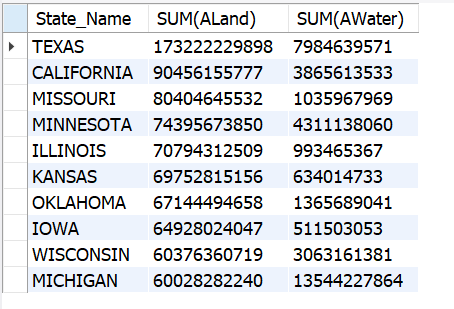
Land and Water Distribution by State
SELECT State_Name, SUM(ALand), SUM(AWater)
FROM us_household_income
GROUP BY State_Name;
-- Top 10 states by land
SELECT State_Name, SUM(ALand)
FROM us_household_income
GROUP BY State_Name
ORDER BY 2 DESC
LIMIT 10
-- Top 10 states by water
SELECT State_Name, SUM(AWater)
FROM us_household_income
GROUP BY State_Name
ORDER BY 2 DESC
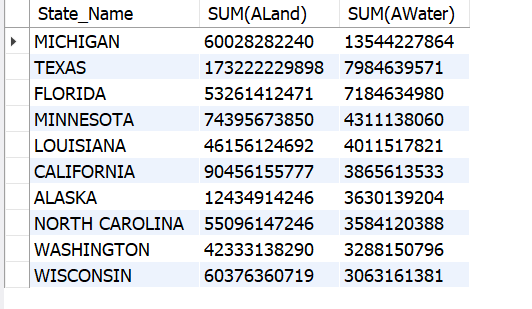
LIMIT 10;Top 10 states by land
Top 10 states by water
Income Analysis by Type
SELECT Type, COUNT(Type),
ROUND(AVG(Mean),2) AS avg_mean,
ROUND(AVG(Median),2) AS avg_median
FROM us_household_income u
INNER JOIN us_household_income_statistics us
ON u.id = us.id
WHERE mean <> 0
GROUP BY Type
ORDER BY avg_mean DESC;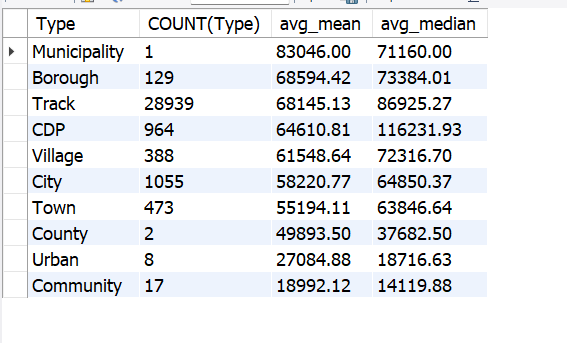
Income Analysis by State
SELECT u.State_Name,
ROUND(AVG(Mean),2) AS avg_mean,
ROUND(AVG(Median),2) AS avg_median
FROM us_household_income u
INNER JOIN us_household_income_statistics us ON u.id = us.id
WHERE mean <> 0
GROUP BY u.State_Name
ORDER BY avg_mean DESC
LIMIT 10;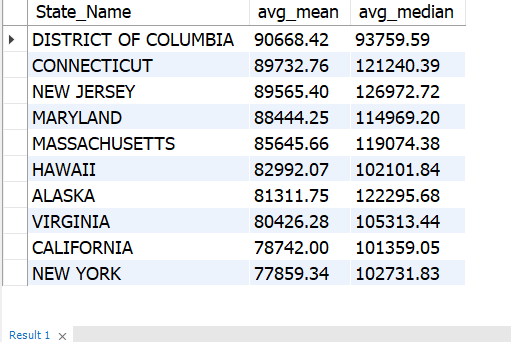
Top Cities by Income
SELECT u.State_Name, City,
ROUND(AVG(Mean),1) AS avg_mean,
ROUND(AVG(Median),1) AS avg_median
FROM us_household_income u
INNER JOIN us_household_income_statistics us ON u.id = us.id
WHERE mean <> 0
GROUP BY u.State_Name, City
ORDER BY avg_mean DESC
LIMIT 20;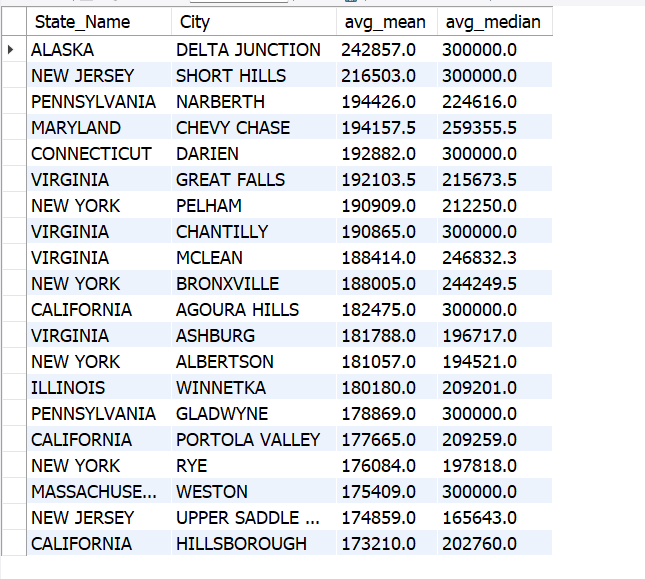
Phase 3: Automated Data Cleaning
Objective: Build a reusable stored procedure to clean data and schedule it for regular execution.
Stored Procedure: Copy_and_Clean_Data
DELIMITER $$
DROP PROCEDURE IF EXISTS Copy_and_Clean_Data;
CREATE PROCEDURE Copy_and_Clean_Data()
BEGIN
CREATE TABLE IF NOT EXISTS us_household_income_clean (...);
INSERT INTO us_household_income_clean
SELECT *, CURRENT_TIMESTAMP()
FROM us_household_income_backup;
DELETE FROM us_household_income_clean
WHERE row_id IN (
SELECT row_id FROM (
SELECT row_id, id,
ROW_NUMBER() OVER(PARTITION BY id, TimeStamp ORDER BY id, TimeStamp) AS row_num FROM us_household_income_clean) row_tab
WHERE row_num > 1
);
UPDATE us_household_income_clean
SET State_Name = 'Georgia'
WHERE State_Name = 'Georia';
UPDATE us_household_income_clean
SET Type = 'CDP'
WHERE Type = 'CPD';
UPDATE us_household_income_clean
SET Type = 'Borough'
WHERE Type = 'Boroughs';
UPDATE us_household_income_clean
SET County = UPPER(County);
UPDATE us_household_income_clean
SET City = UPPER(City);
UPDATE us_household_income_clean
SET Place = UPPER(Place);
UPDATE us_household_income_clean
SET State_Name = UPPER(State_Name);
END $$
DELIMITER ;
Scheduling the Procedure
CREATE EVENT run_data_cleaning
ON SCHEDULE EVERY 30 DAY
DO CALL Copy_and_Clean_Data;Final Reflection
"This project helped me strengthen my SQL skills across data cleaning, analysis, and automation. I learned how to structure queries for clarity, build reusable procedures, and uncover meaningful insights from raw data. It also taught me the importance of designing scalable workflows — something I'm excited to apply in future projects."

🔗 Additional Resources
📂 Full SQL Code on GitHub:
🖥️ Project Summary & Visuals: You’re already here! This post walks through the project phases with explanations and screenshots.
“This post summarizes the project. For full SQL scripts and automation logic, visit the GitHub repo.”


Comments